はじめに
テックリードの柿崎です。私たちは、機械学習のパラメータチューニングを効率よく行うため、KubernetesネイティブのワークフローエンジンであるArgo Workflowsを採用しています。この記事では、その導入手順の要点を紹介いたします。
導入の目的
Argo Workflows導入以前は機械学習のパラメータチューニングを行うにあたり以下の機能を独自に実装しており、属人化していました。
- パラメータ探索のアルゴリズム
- インスタンスのスケーリング
- インスタンスの稼働状況の可視化
- ジョブの進行状況の可視化
これらをより柔軟に活用できるようにして、開発、更新サイクルを早めていくことが導入の目的です。
前提条件
- Kubernetes(EKS)はすでに構築済みであること
- Kubernetes、Helmについての基本的な知識があること
- Argo Workflowsの基本的な知識があること
Kubernetes、EKSの運用については別で記事を書いていますのでそちらもぜひ御覧ください。
eksのcontainer runtimeをcontainerdに入れ替える手順とその効果
ローカル環境でDocker(docker-compose)とKubernetes(minikube)を接続するtips
1. Argo Workflowsのセットアップ
Helmを使用:
Helmを用いることで、Argo Workflowsを簡単にデプロイできます。公式のドキュメントは以下からご参照ください。
Argo Workflows Helm チャート
認証の設定
Argo Workflowsには3つの認証モードが存在します。私たちはOpenID Connectベースの認証を採用しています。
詳細はこちら
詳細設定はserver設定のssoの中で行います。
server: sso: ## All the values are required. SSO is activated by adding --auth-mode=sso ## to the server command line. # ## The root URL of the OIDC identity provider. issuer: ${issuer} ## Name of a secret and a key in it to retrieve the app OIDC client ID from. clientId: name: argo-server-sso key: client-id ## Name of a secret and a key in it to retrieve the app OIDC client secret from. clientSecret: name: argo-server-sso key: client-secret ## The OIDC redirect URL. Should be in the form <argo-root-url>/oauth2/callback. redirectUrl: https://${hostname}/oauth2/callback
artifact repositoryの設定
artifact respositoryはワークフローを実行する際の入出力ファイルの置き場として使われます。s3バケットをartifact respositoryとして設定する方法を示します。
server: artifactRepository: # -- Archive the main container logs as an artifact archiveLogs: false # -- Store artifact in a S3-compliant object store # @default -- See [values.yaml] s3: bucket: ${artifact_bucket} endpoint: s3.amazonaws.com region: ap-northeast-1 # Note the `key` attribute is not the actual secret, it's the PATH to # the contents in the associated secret, as defined by the `name` attribute. insecure: false useSDKCreds: false
controllerの設定
Argo Workflowsのcontrollerはワークフローの実行を制御するキーパーツです。controllerの設定は様々ありますが、以下は主要な設定の詳細になります。 Argo Workflowsのバージョンにより、いくつかの設定点が異なります。ここではv3.4を基準に説明します。
containerRuntimeExecutor
Argo Workflowsでは、ワークフロー内のタスクを実行するためのコンテナランタイム実行環境を選択することができます。以下の実行環境が提供されています:
- docker : Docker APIを使用。
- kubelet : Kubelet APIを直接使用してコンテナを実行。
- emissary : サイドカーコンテナを使用してコンテナの情報を共有。v3.4以降で推奨。
現在の推奨環境であるemissaryを使用する設定例:
controller: containerRuntimeExecutor: emissary
ARGO_PROGRESS_PATCH_TICK_DURATION
v3.4以降で、ワークフローの進行状況をカスタム表示できるようになりました。デフォルトでは、進行状況の更新頻度は1分です。もし進行状況をより頻繁に更新したい場合は、この設定を変更します。
10秒ごとに更新する設定例:
controller: extraEnv: - name: ARGO_PROGRESS_PATCH_TICK_DURATION value: 10s
ttlStrategy
ワークフローの完了後に、どのように古いワークフローリソースを削除するかを制御します。ワークフローリソースが長期間保持されることは、クラスタのリソースを占有し続けるため推奨されません。
完了したワークフローは7日後に削除する設定例:
controller: workflowDefaults: ttlStrategy: secondsAfterCompletion: 592200
ingressの設定
Argo Workflowsへのアクセスを設定します。パブリックネットワークのALBを使ってArgo Workflowsへアクセスできるようにするには次のような設定をします。(EKS側でExternal DNSとAWS Load Balancer Controllerの導入が必要です)
ingress: # -- Enable an ingress resource enabled: true # -- Additional ingress annotations annotations: kubernetes.io/ingress.class: alb alb.ingress.kubernetes.io/scheme: internet-facing alb.ingress.kubernetes.io/target-type: ip alb.ingress.kubernetes.io/listen-ports: '[{"HTTP": 80}, {"HTTPS": 443}]' alb.ingress.kubernetes.io/certificate-arn: ${certificate_arn} alb.ingress.kubernetes.io/subnets: ${subnet_ids} alb.ingress.kubernetes.io/actions.ssl-redirect: '{"Type": "redirect", "RedirectConfig": { "Protocol": "HTTPS", "Port": "443", "StatusCode": "HTTP_301"}}' external-dns.alpha.kubernetes.io/hostname: ${hostname}
これらの設定を適切に調整することで、Argo Workflowsの運用効率とスケーラビリティを最適化することができます。
2. モニタリング・可視化のセットアップ
リソース監視と可視化は、システムの健全な運用のために不可欠です。Argo Workflowsはサーバ上でワークフローを可視化する機能を備えています。
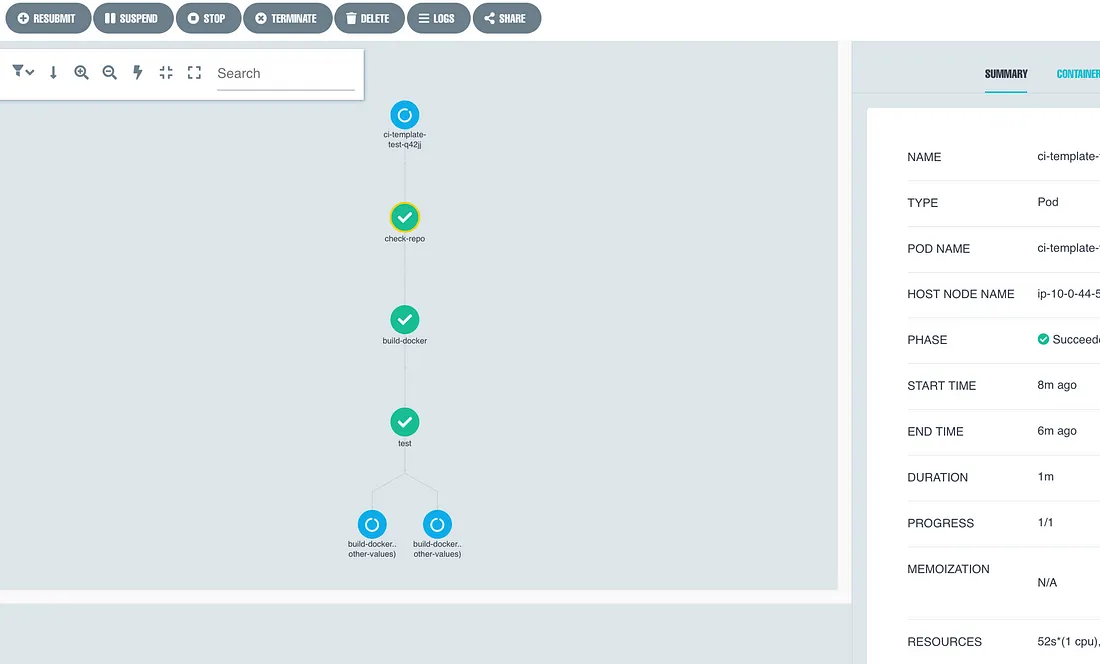
さらに私たちはEKSクラスタのリソース使用状況を監視するために、cAdvisor, Prometheus, そして Grafana の組み合わせを使用しています。
cAdvisor
cAdvisorはPodのリソース使用状況やパフォーマンスメトリクスを自動的に収集するツールです。これにより、Podが消費するCPU、メモリ、ネットワークIO、ディスクIOなどのメトリクスを取得できます。
Prometheus
Prometheusはオープンソースのモニタリング&アラートツールで、cAdvisorやkube-state-metricsといったデータソースからメトリクスを収集して保存します。
AWS Managed Service for Prometheus (AMP)
AMPはAWSが提供するマネージドなPrometheusサービスで、安定的な運用とスケーラビリティが特徴です。また、従量課金モデルのため、必要なメトリクスだけを効率的に収集・保存することが推奨されます。
Helmを使用:
Helmを用いることで、Prometheusを簡単にデプロイできます。公式のドキュメントは以下からご参照ください。
Prometheus Helm チャート
Grafana
Grafanaはダッシュボードを提供する可視化ツールで、Prometheusと連携して、取得したメトリクスを視覚的に分析することができます。 一例ですが、以下のようなダッシュボードが作成できます。
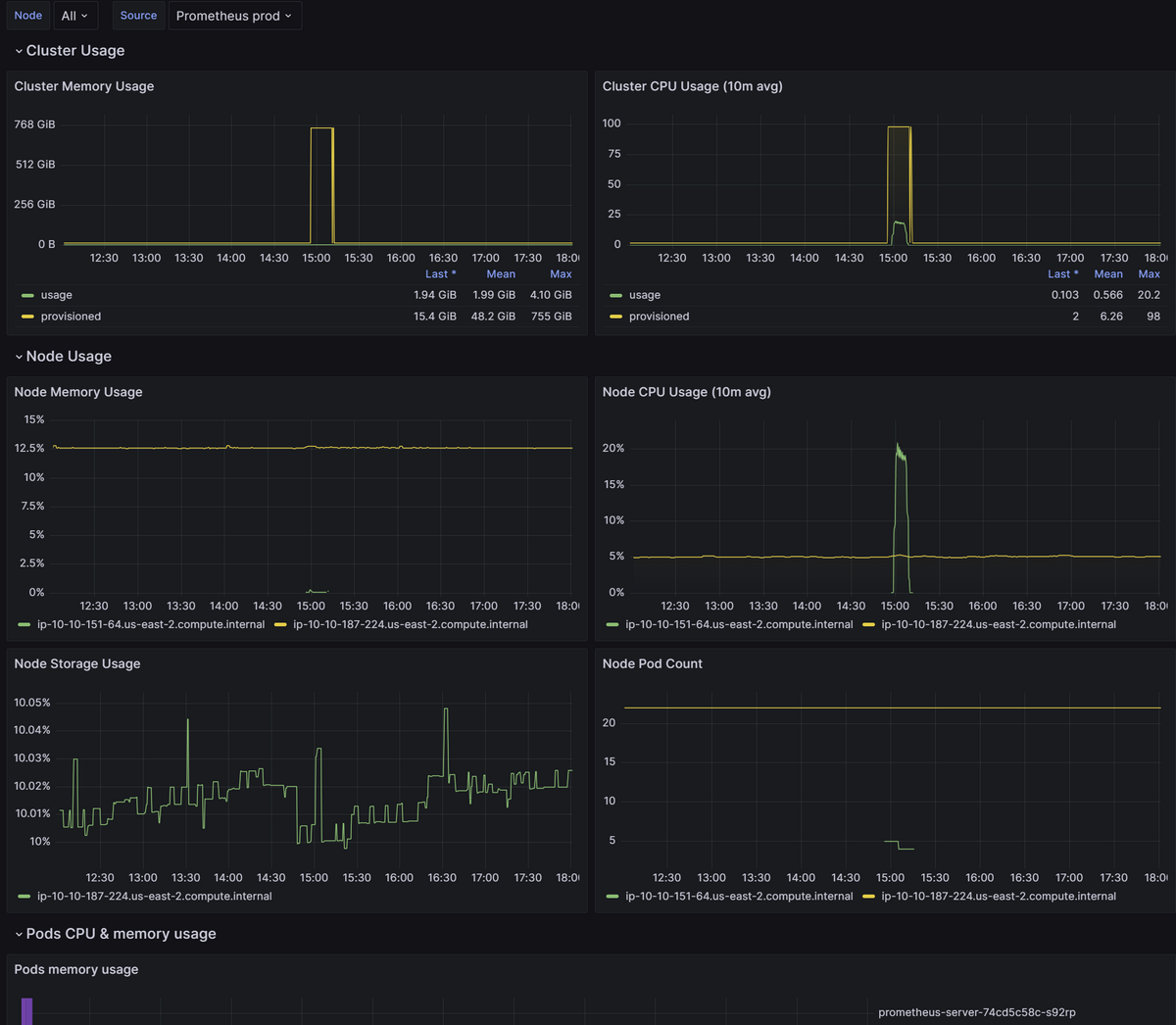
このように、クラスタのリソース使用状況などをリアルタイムで可視化することが可能となります。
上記のツールを組み合わせることで、機械学習のジョブの実行状況やクラスタの健康状態を的確に把握し、必要に応じてリソースの調整や最適化を行うことができます。
おわりに
以上、Argo Workflowsを活用した機械学習環境の構築についての解説でした。 Argo Workflowsの導入により、目的としていた以下のメリットを実感することができました。
- 機械学習のパラメータ探索における柔軟性の向上
- インスタンスのスケーリングの柔軟性の向上
- インスタンスの稼働状況の可視化
- ジョブの進行状況の可視化
今後もこの技術を活用し、更に効率的な機械学習の運用を目指してまいります。
